简述
本文用仿真工具录制下训练数据后,存到本地CSV文件中,本文仅用方向盘转角速度进行训练。
代码示例采用Jupyter编码,如在其他编辑器运行问题,请使用Jupyter.
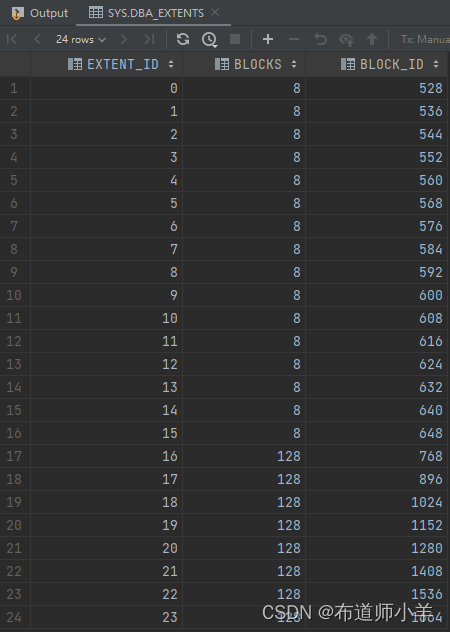
CSV文件中存储的数据如下:
- "center","left","right","steering","throtlle","reverse","speed"
- 中间摄像头图片路径,左侧摄像头图片路径,右侧摄像头图片路径,方向盘角度,油门,速度
模型训练过程
数据分析与预处理
代码示例:
import numpy as np
import pandas as pd
# 读取数据
data = pd.read_csv('driving_log.csv',names=["center","left","right","steering","throtle","reverse","speed"])
# 数据展示
# 把方向盘的转角数据分成20份
counts,angle = np.histogram(data["steering"],20)
# angle有21个数据,把两次数据加在一起再求个平均,就只有20份数据了,这是中心点坐标
center = (angle[1:]+angle[:-1])/2
import matplotlib.pyplot as plt
# 柱状图展示自动驾驶数据分布情况:可以看出来角度为0直行的数据过多,需要进行剪裁
# plt.bar(center,counts,width=0.1)
# 数据清洗:根据数据的分布规律,把结果一直一些特别多的训练数据给删除掉
# 过滤出直行的数据
# 记录所有的直行数据的位置信息
li = []
for i in range(0,len(data["steering"])):
if data["steering"][i] == 0:
li.append(i)
# print(len(li))
# 画线,从中间切一刀
# plt.plot((-1,1),(300,300))
# plt.bar(center,counts,width=0.1)
# 洗牌操作,只保留300 条记录
np.random.shuffle(li)
rm_list = li[300:]
# np.drop 丢弃某些数据, 参数inplace=True: 在原来的数据集上操作
data.drop(rm_list, inplace=True)
counts,angle = np.histogram(data["steering"],20)
# angle有21个数据,把两次数据加在一起再求个平均,就只有20份数据了,这是中心点坐标
center = (angle[1:]+angle[:-1])/2
plt.bar(center,counts,width=0.1)
info = data[["center","steering"]]
info.to_csv("info.csv")



![[Leetcode]用栈实现队列](https://img-blog.csdnimg.cn/direct/52fabee278f54153a9d72aa18e2c4192.png)